

Учебная работа. Реферат: Основные понятия режимов компьютерной обработки данных
Введение. 4
I Теоретическая часть.5
1.1Основные понятия режимов компьютерной обработки данных. 5
1.2систематизация режимов компьютерной обработки данных.6
1.3Способы обработки данных. 12
1.4Система хранение данных.15
Заключение.19
II Практическая часть.20
2.1Общая черта задачки.20
2.2Описание метода решения задачки.22
Перечень литературы.26
Введение
В истинное время компьютеризация крепко вошла в нашу жизнь. При помощи компа можно производить разные операции.
Может быть внедрение компов в области обработки и анализа данных для юзеров из разных сфер деятель.
Компьютерной обработкой данных именуется хоть какой процесс ,который употребляет компьютерную программку для ввода данных ,обобщать их, рассматривать либо другим образом преобразовывать данные в полезную информацию.
Компьютерная интерактивная система, преследует конкретно такие цели которые дозволили бы отдать юзеру, не являющемуся спецом в области компьютерных технологий и в области обработки данных, возможность хорошо и неоднозначно провести анализ статистических данных, не углубляясь в особые и довольно сложные математические расчеты.
I Теоретическая часть.
1.1Основные понятия режимов компьютерной обработки данных
ЭВМ –
электронно-вычислительная машинка.
Информационные системы —
В широком смысле информационная система есть совокупа технического, программного и организационного обеспечения, В узеньком смысле информационной системой именуют лишь подмножествокомпонентов ИС в широком смысле, включающее базы данных, СУБД и спец прикладные программки.
ПЭВМ
— Индивидуальный комп индивидуальная ЭВМ — комп, созданный для личного использования, стоимость, размеры и способности которого удовлетворяют запросам огромного количества людей.
СОД
– Система обработки данных.
Обработка данных —
процесс выполнения последовательности операций над данными. Обработка данных может осуществляться в интерактивном и фоновом режимах.
ВЦ –
вычислительный центр.
ВС –
Вычислительная система
СХД –
система хранения данных.
ГВС, Глобальная вычислительная сеть —
компьютерная сеть, обхватывающая огромные местности и включающая в себя 10-ки и сотки тыщ компов.
1.2систематизация режимов компьютерной обработки данных.
Есть разные режимы компьютерной обработки данных, зависящие сначала от ЭВС, от режимных способностей технических средств, требований к быстроте обработки сообщений.[1]

 Режимы компьютерной обработки данных.
Режимы компьютерной обработки данных.
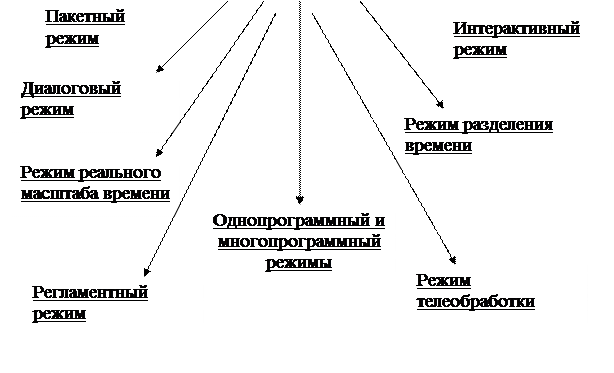
Пакетный режим —
Пакетный режим может понадобиться и при разработке в особенности длинноватых запросов, а конкретно — многострочных установок либо огромных последовательностей установок, он дозволяет отлично применять имеющиеся ресурсы. Пакетная обработка данных — организация выполнения нескольких программ в определенной последовательности при помощи установок операционной системы. Пакетная обработка организуется при помощи пакетных файлов, т.е. юзер, собирая информацию, сформировывает её в пакеты в согласовании с признаками и задачками. Опосля сбора инфы происходит ёё обработка и ввод. Этот режим употребляется, как правило, при централизованном методе обработки инфы [2]
.
Интерактивный режим –
Интерактивность понятие, которое открывает нрав и степень взаимодействия меж объектами. Употребляется в областях: теория инфы, информатика и программирование, системы телекоммуникаций, социология, промышленный и остальных. Это принцип организации системы, при котором цель достигается информационным обменом частей данной для нас системы.[3]
При использовании интерактивный режим у юзера возникает возможность повлиять на процесс обработки данных.
Диалоговый режим-
метод взаимодействия юзера либо оператора с ЭВМ , при котором происходит конкретный и обоесторонний обмен информацией, командами либо инструкциями меж человеком и ЭВМ . Диалоговый режим предполагает такую скорость обработки данных, которая не сказывается на технологии действий юзера. Различают активные и пассивные диалоговые режимы.[4]
Этот режим просит определенного уровня технической оснащенности юзера, т.е. наличие терминала либо ПЭВМ, связанных с центральной вычислительной системой каналами связи.
Диалоговый режим
Активный
Пассивный
Активный диалог — режим взаимодействия юзера и программной системы, который характеризуется равноправием его участников. Обычно для организации активного диалога употребляются директивные (командные) языки, либо языки, близкие к естественным.
Пассивный диалог — режим взаимодействия юзера и программной системы, инициатива ведения которого принадлежит программной системе. При всем этом программная система ведет за собой юзера, требуя от него в точках ветвления вычислительного процесса доп информацию, нужную для принятия заложенных в метод решений. В пассивном диалоге программная система обеспечивает юзера информационными сообщениями и подсказками, облегчающими внедрение диалоговой системы. Запросы к юзеру строятся обычно или в виде меню, или в виде шаблонов.
Режим разделения времени —
подразумевает способность системы выделять свои ресурсы группе юзеров попеременно. Вычислительная система так стремительно обслуживает всякого юзера, что создается воспоминание одновременной работы нескольких юзеров. Таковая возможность получается из-за соответственного программного обеспечения.
Режим настоящего масштаба времени —
Реальное время — режим работы вычислительной системы, при котором время отклика на событие не превосходит предопределенной величины. Обработка данных в настоящем масштабе времени это обработка данных, протекающая с таковой же скоростью что и моделируемые действия. Как правило, этот режим употребляется при децентрализованной и распределенной обработке данных.[5]
Регламентный режим —
характеризуется определенностью во времени отдельных задач юзера. Например, получение результатных сводок по окончании месяца, расчет ведомостей начисления заработной платы к определенным датам и т.д. Сроки решения инсталлируются заблаговременно по регламенту в противоположность к произвольным запросам.
Режим телеобработки —
Телеобработка (удаленная обработка) – режим обработки данных при содействии юзеров с СОД через полосы связи. Телеобработка рассматривается в качестве самостоятельного режима обработки данных по последующим причинам. Во-1-х, удаленность юзеров от СОД и наличие меж ними специфичного средства передачи данных – полосы связи – порождает необходимость в особых действиях юзеров при организации доступа к системе и окончании сеанса работы. Во-2-х, наличие линий связи налагает ограничения на форму и время обмена данными меж юзерами и СОД. Эти ограничения приводят к необходимости особых методов организации данных и доступа к ним, что в свою очередь отражается на структуре прикладных программ, применяемых в режиме телеобработки.
Режим телеобработки характеризуется, до этого всего, специфичностью доступа юзера к системе и системы к данным, передаваемым через удаленные терминалы, т. е. связан сначала с организацией обработки данных снутри СОД. При всем этом юзеры могут работать в режимах пакетном, диалоговом либо «запрос–ответ». Любой из этих режимов характеризуется специфическим методом взаимодействия юзеров с системой и подходящим временем ответа.[6]
Однопрограммный и многопрограммный режимы — Однопрограммный режим.
Из приготовленных заданий юзеров составляется пакет заданий. машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор обслуживает программки юзеров строго в порядке их следования в пакете. процесс выполнения очередной программки не прерывается до полного ее окончания. Лишь опосля этого машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор как ресурс отдается в монопольное владение последующей очередной программке.

Режим конкретного доступа-
юзер получает ЭВМ в полное распоряжение: он сам готовит ЭВМ к работе, загружает задания, инициирует их, следит за ходом решения и выводом результатов. По окончании работ 1-го юзера все ресурсы ЭВМ передаются в распоряжение другого
Режим косвенного доступа-
юзер не имеет прямого контакта с ЭВМ . Режим косвенного доступа имеет значимый недочет. Он не дозволяет стопроцентно исключить случаи простоя микропроцессора либо непродуктивного его использования. Каждый раз, когда еще одна программка, вызванная в микропроцессор, за ранее не обеспечена данными, машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор обязан простаивать. При всем этом резко понижается эффективность использования ЭВМ .
Многопрограммный режим-
дозволяет сразу обслуживать несколько программ юзеров. Виды многопрограммной работы: традиционное мультипрограммирование, режим разделения времени, режим настоящего времени и целый ряд производных от их. Режим традиционного мультипрограммирования, либо пакетной обработки, применительно к однопроцессорным ЭВМ является основой для построения всех остальных видов многопрограммной работы. Режим имеет целью обеспечить малое время обработки пакета заданий и очень загрузить машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор.

Однопрограммный и многопрограммный режимы охарактеризовывают возможность системы работать сразу по одной либо нескольким программкам.
1.3 методы обработки данных
Методы обработки данных делятся на централизованный, децентрализованный, распределительный и встроенный методы
1.
Централизованный
— обрабатывает данные в одном месте, используя мощнейший комп и сложное программное обеспечение, установленное лишь на нем. Терминалы юзеров и автоматические устройства ввода первичных документов отправляют данные на центральную ЭВМ для обработки, которая, если нужно, предоставляет на терминалы обработанные данные.Преимуществами такового подхода являются наименьшие Издержки, наилучший контроль за данными и программками (так как они находятся в одном месте), большая сохранность.Посреди недочетов — большая сложность эксплуатации, высочайшие Издержки на коммуникации (при большенный удаленности терминалов).

2.
Децентрализованный —
системы,в каких данные хранятся и обрабатываются независимо в различных местах. При всем этом на любом компе хранится некое подмножество всех данных компании, а часть данных находится в нескольких местах.
3.
Распределительный –
метод, при котором все подразделения компании, находящиеся в различных местах, соединены в единую сеть. Каждое из их имеет средства и способности без помощи других обрабатывать свои данные, потому пользуется преимуществами децентрализованной обработки. В то же время локальные компы из различных мест могут посылать данные на центральную ЭВМ для подведения итогов и воспользоваться общими данными компании, находящимися на ней, потому распределенная обработка дает и достоинства централизованной системы. В итоге выходит система, направленная как на нужды юзеров, так и на нужды управления компании.

· Так как юзеры контролируют каждую локальную систему, они имеют возможность подогнать ее под свои нужды и тем сделать лучше свойство производимой инфы.
· Распределенная обработка данных дозволяет резвее и поточнее вводить и корректировать данные, резвее получать ответы на запросы.
· Уменьшаются Издержки на коммуникации, т.к. обработка делается локально.
· Так как данные и остальные ресурсы находятся в различных местах и отчасти дублируются, компы вроде бы страхуют друг дружку, понижая возможность чертовских утрат.
· Любая локальная система может рассматриваться как модуль общей системы, который быть может добавлен, изменен либо удален из системы без необходимости изменять остальные модули.
· Распределенные системы наиболее дороги, чем централизованные.
· Намного усложняются задачки обслуживания оборудования, программного обеспечения, поддержания данных в нужном состоянии.
· Так как данные принадлежат различным подразделениям, безизбежно их дублирование со всеми вытекающими последствиями от использования таковой инфы, потому возникает необходимость особых процедур по согласованию содержимого общих частей баз данных.
· Так как безизбежно распределение возможностей и зон ответственности в таковой системе, намного усложняется процесс документирования и контроля.
· Разбросанность частей системы в пространстве и наличие коммуникаций понижают способности обеспечения сохранности.
· Миниатюризируется информационная насыщенность каждой отдельной локальной системы, так как вся информация, которая присуща централизованным системам, не быть может продублирована на всех компах.
4.
Встроенный —
метод обработки инфы. Он предугадывает создание информационной модели управляемого объекта, другими словами создание распределенной базы данных. Таковой метод обеспечивает наибольшее удобство для юзера.
1.4 Система
хранение данных.
системы хранения данных (СХД) обеспечивают действенное хранение и оперативный доступ к инфы. Благодаря достижениям в современной технологии, хранение огромных объёмов инфы сделалось достаточно лёгкой задачей. Существует огромное количество разных типов электрических устройств, применяемых для хранения данных. Самые обыденные методы хранения данных, применяемые юзерами:
— хранение на магнитных и оптических носителях;
— на сменном носителе либо, как молвят, инфы.
Система хранения данных содержит последующие подсистемы и составляющие: конкретно устройства хранения (дисковые массивы, ленточные библиотеки), инфраструктуру доступа к устройствам хранения, подсистему запасного копирования и архивирования данных.
В случае отдельного ПК под системой хранения данных можно осознавать внутренний твердый диск либо систему дисков (RAID массив). Если же речь входит о системах хранения данных различного уровня компаний, то обычно можно выделить три технологии организации хранения данных:
- Direct Attached Storage (DAS);
- Network Attach Storage (NAS);
- Storage Area Network (SAN)
Устройства DAS (Direct Attached Storage)
– решение, когда устройство для хранения данных подключено конкретно к серверу, либо к рабочей станции, как правило, через интерфейс по протоколу SAS.
Главные достоинства и недочеты сотворения хранилищ данных на базе сети DAS:
Плюсы:
- Довольно низкая стоимость. На самом деле эта СХД представляет собой дисковую корзину с твердыми дисками, вынесенную за границы сервера.
- Простота развертывания и администрирования.
- Высочайшая скорость обмена меж дисковым массивом и сервером.
Минусы:
- Низкая надежность. При выходе из строя сервера, к которому подключено данное хранилище, данные перестают быть доступными.
- Низкая степень консолидации ресурсов – вся ёмкость доступна одному либо двум серверам, что понижает упругость распределения данных меж серверами. В реультате нужно закупать или больше внутренних твердых дисков, или ставить доп дисковые полки для остальных серверных систем
- Низкая утилизация ресурсов.
Устройства NAS (Network Attached Storage)
– раздельно стоящая встроенная дисковая система, по-сути, NAS-cервер, со собственной спец ОС и набором нужных функций резвого пуска системы и обеспечения доступа к файлам. Система подключается к обыкновенной компьютерной сети (ЛВС), и являющается резвым решением препядствия нехватки вольного дискового места, доступного для юзеров данной сети.
Главные достоинства и недочеты сотворения хранилищ данных на базе сети N
AS
:
Плюсы:
- Дешевизна и доступность его ресурсов не только лишь для отдельных серверов, да и для всех компов организации.
- Простота коллективного использования ресурсов.
- Простота развертывания и администрирования
- Универсальность для клиентов (один сервер может обслуживать клиентов MS, Novell, Mac, unix)
Минусы:
- Доступ к инфы через протоколы “сетевых файловых систем” часто медлительнее, чем как к локальному диску.
- Большая часть дешевых NAS-серверов не разрешают обеспечить высокоскоростной и гибкий способ доступа к данным на уровне блоков, присущих SAN системам, а не на уровне файлов.
Storage Area Network (SAN)
–это особая выделенная сеть, объединяющая устройства хранения данных с серверами приложений, обычно строится на базе протокола Fibre Channel либо протокола iSCSI.
Главные достоинства и недочеты сотворения хранилищ данных на базе сети SAN:
Плюсы:
- Высочайшая надёжность доступа к данным, находящимся на наружных системах хранения. Независимость топологии SAN от применяемых СХД и серверов.
- Централизованное хранение данных (надёжность, сохранность).
- Комфортное централизованное управление коммутацией и данными.
- Перенос интенсивного трафика ввода-вывода в отдельную сеть, разгружая LAN.
- Высочайшее быстродействие и низкая латентность.
- Масштабируемость и упругость логической структуры SAN
- Возможность организации запасных, удаленных СХД и удаленной системы бэкапа и восстановления данных.
- Возможность строить отказоустойчивые кластерные решения без доп издержек на базе имеющейся SAN.
Минусы:
- Наиболее высочайшая стоимость
- Сложность в настройке FC-систем
- Необходимость сертификации профессионалов по FC-сетям (iSCSI является наиболее обычным протоколом)
- Наиболее твердые требования к сопоставимости и валидации компонент.
- Возникновение в силу накладности DAS-«островов» в сетях на базе FC-протокола, когда на предприятиях возникают одиночные серверы с внутренним дисковым местом, NAS-серверы либо DAS-системы в силу нехватки бюджета.
Заключение.
Обработка инфы в современной информатике производится компом и нередко включает хранение данных с внедрением наружной памяти. Резвый рост размеров информационных ресурсов просит принципно новейших подходов к хранению и обработке данных. Обработка инфы делает определенные цели и задачки.
Обычными целями обработки данных является собрать всю доступную информацию, представленную в данных различной природы; представить существенную информацию в виде, более комфортном для восприятия юзера. Эти цели, в свою очередь, приводят к постановке задач обработки данных
II
Практическая часть.
2.1Общая черта задачки.
В течение текущего денька в салоне сотовой связи проданы мобильники, код, модель и стоимость которых указаны в таблице на рис. 1. В таблице на рис. 2 указан код и количество проданных телефонов разных моделей.
— В итоговой таблице (рис.3) обеспечить автоматическое наполнение данными столбцов «Модель мобильного телефона», «Стоимость, руб.», «Продано, шт.», используя начальные данные таблиц на рис.1 и рис.2, а так же функции ЕСЛИ(), ПРОСМОТР. Высчитать сумму, полученную от продаж каждой моделей, итоговую сумму продаж.
— Сформировать ведомость продаж мобильников на текущую дату.
— Представить графически данные о продаже мобильников за текущий денек.
Код мобильного телефона
Модель мобильного телефона
Стоимость, руб.
108
Fly Z500
7899
109
FlyX3
4819
209
LG-C3400
6540
210
LG-F1200
10419
308
Motorola V180
3869
309
Motorola V220
4459
301
Motorola C115
1570
304
Motorola C390
5149
406
Nokia 3220
4299
407
Nokia 3230
10490
408
Nokia 5140
6349
503
Pantech G-670
7659
504
Pantech GB-100
3789
604
Siemens A65
2739
605
Siemens A75
2869
708
Sony Ericsson T290i
2569
709
Sony Ericsson Z800i
13993
Рис 1. Данные таблицы «Модели и цены»
№ реализации
Код мобильного телефона
Продано, шт.
1
109
4
2
209
2
3
304
1
4
406
5
5
408
3
6
503
4
7
605
8
8
708
6
Рис 2. Перечень продаж
Код мобильного телефона
Модель мобильного телефона
Стоимость, руб.
Продано, шт.
Сумма, руб.
109
209
304
406
408
503
605
708
ИТОГО
Рис 3.Табличные данные ведомости продаж
2.2Описание метода решения задачки.
1. Запустить табличный микропроцессор MS Excel.
2. Лист 1 переименовать в лист с заглавием Данные модели и цены.
3. На листе Данные модели и цены MS Excel сделать таблицу
4. Заполнить таблицу модели и цены начальными данными (рис. 4)

Рис 4.
5 Лист 2 переименовать в лист с заглавием Перечень продаж.
6. На листе Перечень продаж MSExcel сделать таблицу, в какой будет перечень кодов проданных телефонов, количество и номер реализации.
7. Заполнить таблицу «Перечень продаж» (рис. 5)
 рис 5
рис 5
8. Создать структуру шаблона таблицы «Табличные данные ведомости продаж» (рис. 6)
Колонка электрической таблицы
Наименование (реквизит)
Тип данных
формат данных
длина
точность
1
Код мобильного телефона
числовой
3
2
Модель мобильного телефона
текстовый
50
3
Стоимость, руб.
числовой
3
2
4
Продано, шт.
числовой
5
5
Сумма, руб.
числовой
5
2
Рис. 6.

10. Заполняем графу Модель мобильного телефона таблицы «Табличные данные ведомости продаж» на листе Табличные данные ведомости продаж последующим образом:
Занести в ячейку 22 формулу:
=ЕСЛИ(22=»»;»»;ПРОСМОТР(22;Данные модели и цены!$2$2:$2$18;Данные модели и цены!$3$3:$3$18)).
Размножить введенную в ячейку 22 формулу для других ячеек (с 22 по 29) данной графы.
Таки м образом, будет выполнен цикл, управляющим параметром которого является номер строчки.

11. Аналогично заполняем графы Стоимость, Продано.

12. заполняем графу Сумма, для этого в ячейке 52 записываем формулу: =32*42. Размножаем эту формулу по ячейкам (с 52 по 59)

13. заполняем ячейку 510: = сумм (52:59) получим итоговую сумму по проданным телефонам.

14. Строим график и сохраняем его на отдельном листе, который переименовываем в График

Перечень литературы.
1)
Е. Г. Ясин. Встроенные системы обработки данных.
2)
. Базы теории вычислительных систем: Учебное пособие / Под ред. С.А. Майорова. М.: Высшая школа, 1999.
3)
Позин И.Л., Щербо В.К. Телеобработка данных в автоматических системах. М.: Статистика, 2000.
4)
Вычислительные сети и сетевые протоколы/ Д. Дэвис, Д. Барбер, У. Прайс, С. Соломонидес: Пер. с англ. М.: мир, 1982.
5)
Пышкин Е.В. Структурное проектирование: основание и развитие
способов. – СПб.: Изд-во Политехн. ун-та, 2005.
[1]
Е. Г. Ясин. Встроенные системы обработки данных
[2]
Ясин Е.Г. Системы обработки данных.
[3]
HTTP://ru.wikipedia.ru
[4]
«Денежный словарь Финам»
[5]
Ясин Е.Г. системы обработки данных
[6]
Позин И.Л., Щербо В.К. Телеобработка данных в автоматических системах. М.: Статистика, 2000.
]]>