

Учебная работа. Реферат: Типы кэш-памяти
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП либо наружное по отношению к ЦП. кэш служит скоростным буфером меж ЦП и относительно неспешной главный памятью. Мысль кэш-памяти базирована на прогнозировании более возможных воззваний ЦП к оперативки. В базу такового подхода положен принцип временной и пространственной локальности программки.
Если ЦП обратился к какому-либо объекту оперативки, с высочайшей толикой вероятности ЦП скоро опять обратится к этому объекту. Примером данной для нас ситуации быть может код либо данные в циклах. Эта теория описывается принципом временной локальности, в согласовании с которым нередко применяемые объекты оперативки должны быть «поближе» к ЦП (в кэше).
Для согласования содержимого кэш-памяти и оперативки употребляют три способа записи:
·
·
·
Обычно, все способы записи, не считая сквозной, разрешают для роста производительности откладывать и группировать операции записи в оперативную память.
·
·
место памяти отображения данных в кэше разбивается на строчки — блоки фиксированной длины (к примеру, 32, 64 либо 128 б). Любая строчка кэша может содержать непрерывный выровненный блок б из оперативки. Какой конкретно блок оперативки отображен на данную строчку кэша, определяется тегом строчки и методом отображения. По методам отображения оперативки в кэш выделяют три типа кэш-памяти:
·
·
·
Для вполне ассоциативного кэша типично, что кэш-контроллер может поместить хоть какой блок оперативки в всякую строчку кэш-памяти (рис.
). В этом случае физический адресок разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответственной строчки. Когда ЦП обращается к кэшу за нужным блоком, кэш-промах будет найден лишь опосля сопоставления тегов всех строк с номером блока.
Одно из главных плюсов данного метода отображения — отменная утилизация оперативки, т.к. нет ограничений на то, какой блок быть может отображен на ту либо иную строчку кэш-памяти. К недочетам следует отнести сложную аппаратную реализацию этого метода, требующую огромного количества схемотехники (в главном компараторов), что приводит к повышению времени доступа к такому кэшу и повышению его цены.

Другой метод отображения оперативки в кэш — это кэш прямого отображения (либо одновходовый ассоциативный кэш). В этом случае адресок памяти (номер блока) совершенно точно описывает строчку кэша, в которую будет помещен данный блок. Физический адресок разбивается на три части: смещение в блоке (строке кэша), номер строчки кэша и тег. Тот либо другой блок будет постоянно помещаться в строго определенную строчку кэша, по мере необходимости заменяя собой лежащий там иной блок. Когда ЦП обращается к кэшу за нужным блоком, для определения успешного воззвания либо кэш-промаха довольно проверить тег только одной строчки.
Явными преимуществами данного метода являются простота и дешевизна реализации. К недочетам следует отнести низкую эффективность такового кэша из-за возможных нередких перезагрузок строк. к примеру, при воззвании к каждой 64-й ячейке памяти в системе на рис.
кэш-контроллер будет обязан повсевременно перегружать одну и ту же строчку кэш-памяти, совсем не задействовав другие.

Невзирая на тривиальные недочеты, данная разработка отыскала успешное применение, к примеру, в МП Motorola MC68020, для организации кэша инструкций первого уровня (
). В данном процессоре реализован кэш прямого отображения из 64 строк по 4 б. тег строчки, не считая 24 бит, задающих адресок кэшированного блока, содержит бит значимости, определяющий реальность строчки (если бит значимости 0, данная строчка считается недействительной и не вызовет кэш-попадания). Воззвания к данным не кэшируются.

Компромиссным вариантом меж первыми 2-мя методами является множественный ассоциативный кэш либо частично-ассоциативный кэш (
). При всем этом методе организации кэш-памяти строчки соединяются воединыжды в группы, в которые могут заходить 2, 4, : строк. В согласовании с количеством строк в таковых группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При воззвании к памяти физический адресок разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адресок которого соответствует определенной группе, быть может расположен в хоть какой строке данной для нас группы, и в теге строчки располагается соответственное иной стороны, тот либо другой блок может попасть лишь в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтоб машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор сумел идентифицировать кэш-промах, ему нужно будет проверить теги только одной группы (2/4/8/: строк).

Данный метод отображения соединяет плюсы как вполне ассоциативного кэша (отменная утилизация памяти, высочайшая скорость), так и кэша прямого доступа (простота и дешевизна), только некординально уступая по сиим чертам начальным методам. Конкретно потому множественный ассоциативный кэш более обширно всераспространен (табл. Свойства подсистемы кэш-памяти у ЦП IA-32).
Таблица . Свойства подсистемы кэш-памяти у ЦП IA-32
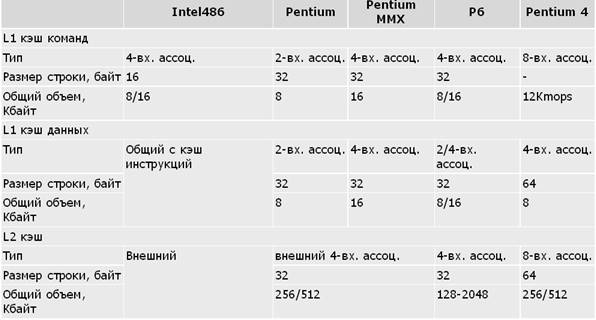
Примечания: В Intel-486 употребляется единый кэш установок и данных первого уровня. В Pentium Pro L1 кэш данных — 8 Кбайт 2-входовый ассоциативный, в других моделях P6 — 16 Кбайт 4-входовый ассоциативный. В Pentium 4 заместо L1 кэша установок употребляется L1 кэш микроопераций (кэш трассы).
Для организации кэш-памяти можно применять принстонскую архитектуру (смешанный кэш для установок и данных, к примеру, в Intel-486). Это явное (и неминуемое для фон-неймановских систем с наружной по отношению к ЦП кэш-памятью) решение не постоянно бывает самым действенным. Разделение кэш-памяти на кэш установок и кэш данных (кэш гарвардской архитектуры) дозволяет повысить эффективность работы кэша по последующим суждениям:
·
·
Конкретно потому все крайние модели IA-32, начиная с Pentium, для организации кэш-памяти первого уровня употребляют гарвардскую архитектуру.
Аспектом действенной работы кэша можно считать уменьшение среднего времени доступа к памяти по сопоставлению с системой без кэш-памяти. В таком случае среднее время доступа можно оценить последующим образом:
Tср = (Thit x Rhit) + (Tmiss x (1 Rhit))
где Thit — время доступа к кэш-памяти в случае попадания (включает время на идентификацию промаха либо попадания), Tmiss — время, нужное на загрузку блока из главный памяти в строчку кэша в случае кэш-промаха и следующую доставку запрошенных данных в машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор, Rhit — частота попаданий.
Разумеется, что чем поближе кэш-памяти и ее объемом. Воздействие наличия и отсутствия кэш-памяти и ее размера на рост производительности ЦП показано в табл.
Таблица. Размер и эффективность кэш-памяти
Размер кэш-памяти
Частота попаданий, %
Рост производительности, %
Нет кэш-памяти, DRAM с 2 TW
—
0
16 Кб
81
35
32 Кб
86
38
64 Кб
88
39
128 Кб
89
39
Нет кэш-памяти, SRAM без TW
—
47
Стратегия размещения.
На сложность этого механизма существенное воздействие оказывает
стратегия размещения, определяющая, в какое пространство кэш-памяти
следует поместить любой блок из главный памяти.
Зависимо от метода размещения данных главный памяти в кэш-памяти существует три типа кэш-памяти:
· кэш с прямым отображением (размещением);
· вполне ассоциативный кэш;
· множественный ассоциативный кэш либо частично-ассоциативный.
кэш с прямым отображением
(размещением) является самым
обычным типом буфера. адресок памяти совершенно точно описывает строчку
кэша, в которую будет помещен блок инфы. При всем этом предпо-
лагается, что оперативная память разбита на блоки и любому та-
кому блоку в буфере отводится всего одна строчка. Это обычный и дешевый в реализации метод отображения. Главный его недочет – твердое закрепление за определенными блоками ОП одной строчки в кэше. Потому, если программка попеременно обращается к словам из 2-ух разных блоков, отображаемых на одну и ту же строчку кэш-памяти, повсевременно будет происходить обновление данной строчки и возможность попадания будет низкой.
кэш с вполне ассоциативным отображением
дозволяет преодолеть недочет прямого, разрешая загрузку хоть какого блока ОП в всякую строчку кэш-памяти. Логика управления выделяет в адресе ОП два поля: поле тега и поле слова. Поле тега совпадает с адресом блока ОП. Для проверки наличия копии блока в кэш-памяти, логика управления кэша обязана сразу проверить теги всех строк на совпадение с полем тега адреса. Ассоциативное отображение обеспечивает упругость при выбирании строчки для вновь записываемого блока. Принципный недочет этого метода – в необходимости использования дорогой ассоциативной памяти.
Множественно-ассоциативный тип либо частично-ассоциативный тип отображения –
это один из вероятных компромиссов, сочетающий плюсы прямого и ассоциативного методов. кэш-память ( и тегов и данных) разбивается на некое количество модулей. Зависимость меж модулем и блоками ОП таковая же твердая, как и при прямом отображении. А вот размещение блоков по строчкам модуля случайное и для поиска подходящей строчки в границах модуля употребляется ассоциативный принцип. Этот метод отображения более обширно всераспространен в современных процессорах.
Отображение секторов ОП в кэш-памяти.
Данный тип отображения применяется во всех современных ЭВМ и заключается в том, что вся ОП разбивается на секторы, состоящие из фиксированного числа поочередных блоков. кэш-память также разбивается на секторы, содержащие такое же количество строк. Размещение блоков в секторе ОП и секторе кэша вполне совпадает. Отображение сектора на кэш-память осуществляется ассоциативно, те хоть какой сектор из ОП быть может помещен в хоть какой сектор кэша. Таковым образом, в процессе работы АЛУ обращается в поисках очередной команды к ОП, в итоге что, в кэш загружается( в случае отсутствия там блока, содержащего эту команду), целый сектор инфы из ОП, при этом по принципу локальности, из-за этого достигается существенное повышение быстродействия системы.
Иерархическая модель кэш-памяти
Как правило, кэш-память имеет многоуровневую архитектуру. к примеру, в компе с 32 Кбайт внутренней (в ядре ЦП) и 1 Мбайт наружной (в корпусе ЦП либо на системной плате) кэш-памяти 1-ая будет считаться кэш-памятью 1-го уровня (L1), а 2-ая — кэш-памятью 2-го уровня (L2). В современных серверных системах количество уровней кэш-памяти может доходить до 4, хотя более нередко употребляется двух- либо трехуровневая схема.
В неких процессорных архитектурах кэш-память 1-го уровня разбита на кэш установок (InstructionCache, I-cache) и кэш данных (DataCache, D-кэш-память 2-го уровня, обычно, унифицирована, т. е. может содержать как команды, так и данные. Если она встроена в ядро ЦП, то молвят о S-случае — о B-наличие интегрированной кэш-памяти 3-го уровня, то ее называют T-кэш-памяти медлительнее, но больше предшествующего по размеру. Если в системе находится B-момент выполнения некой команды в регистрах не окажется данных для нее, то они будут затребованы из наиблежайшего уровня кэш-памяти, т. е. из D-cache. В случае их отсутствия в D-системы (ОС) успевает вытеснить их в файл подкачки на твердый диск. В случае доставки из оперативки утраты времени на получение подходящих данных могут составлять от 10-ов до сотен тактов ЦП, а в случае нахождения данных на твердом диске речь уже может идти о миллионах тактов.
Ассоциативность кэш-памяти
Одна из базовых черт кэш-памяти — уровень ассоциативности — показывает ее логическую сегментацию. Дело в том, что поочередный перебор всех строк кэша в поисках нужных данных востребовал бы 10-ов тактов и свел бы на нет весь выигрыш от использования интегрированной в ЦП памяти. Потому ячейки ОЗУ агрессивно привязываются к строчкам кэш-памяти (в каждой строке могут быть данные из фиксированного набора адресов), что существенно уменьшает время поиска. С каждой ячейкой ОЗУ быть может соединено наиболее одной строчки кэш-памяти: к примеру, n-канальная ассоциативность (n-waysetassociative) обозначает, что информация по некому адресу оперативки может храниться в п мест кэш-памяти.
Выбор места может проводиться по разным методам, посреди которых почаще всего употребляются принципы замещения LRU (LeastRecentlyUsed, замещается запись, запрошенная в крайний раз более издавна) и LFU (LeastFrequentlyUsed, запись, менее нередко запрашиваемая), хотя есть и модификации этих принципов. к примеру, вполне ассоциативная кэшпамять (fullyassociative), в какой информация, находящаяся по произвольному адресу в оперативки, быть может расположена в случайной строке. иной вариант — прямое отображение (directmapping), при котором информация, которая находится по произвольному адресу в оперативки, быть может расположена лишь в одном месте кэш-памяти. Естественно, этот вариант обеспечивает наибольшее быстродействие, потому что при проверке наличия инфы контроллеру придется «заглянуть» только в одну строчку кэша, да и менее эффективен, так как при записи контроллер не будет выбирать «среднее» пространство. При схожем объеме кэша схема с полной ассоциативностью будет менее резвой, но более действенной.
На сто процентов ассоциативный кэш встречается на практике, но, как правило, у него весьма маленький размер. К примеру, в ЦП Cyrix 6×86 использовалось 256 б такового кэша для установок перед унифицированным 16-или 64-Кбайт кэшем L1. Нередко полноассоциативную схему используют при проектировании TLB (о их будет поведано ниже), кэшей адресов переходов, буферов чтения-записи и т. д. Как правило, уровни ассоциативности I-cache и D-cache достаточно низки (до 4 каналов) — их повышение нецелесообразно, так как приводит к повышению задержек доступа и в итоге плохо отражается на производительности. В качестве некой компенсации наращивают ассоциативность S-к примеру, согласно результатам исследовательских работ нередко применяемых целочисленных задач, у IntelPentiumIII 16 Кбайт четырехканального D-кэш-памяти
Немаловажная черта кэш-памяти — размер строчки. Как правило, на одну строчку полагается одна запись адреса (так именуемый тег), которая показывает, какому адресу в оперативки соответствует данная линия. Разумеется, что нумерация отдельных байтов нецелесообразна, так как в этом случае размер служебной инфы в кэше в пару раз превзойдет размер самих данных. Потому один тег обычно полагается на одну строчку, размер которой обычно 32 либо 64 б (реально имеющийся максимум 1024 б), и эквивалентен четырем (время от времени восьми) разрядностям системной шины данных. Не считая того, любая строчка кэш-памяти сопровождается некой информацией для обеспечения отказоустойчивости: одним либо несколькими битами контроля четности (parity) либо восемью и наиболее б обнаружения и корректировки ошибок (ЕСС, ErrorCheckingandCorrecting), хотя в массовых решениях нередко не употребляют ни того, ни другого.
Размер тега кэш-памяти зависит от 3-х главных причин: размера кэш-памяти, наибольшего кэшируемого размера оперативки, также ассоциативности кэш-памяти. Математически этот размер рассчитывается по формуле:
где Stag — размер 1-го тега кэш-памяти, в битах; Smem — наибольший кэшируемый размер оперативки, в б; Scache — размер кэш-памяти, в б; А — ассоциативность кэш-памяти, в каналах.
Отсюда следует, что для системы с 1-Гбайт оперативной памятью и 1-Мбайт кэш-памятью с двухканальной ассоциативностью будет нужно 11 бит для всякого тега. Броско, что фактически размер строчки кэш-памяти никак не влияет на размер тега, но назад пропорционально влияет на количество тегов. Следует осознавать, что размер строчки кэш-памяти не имеет смысла созодать меньше разрядности системной шины данных, но неоднократное повышение размера приведет к чрезмерному засорению кэш-памяти ненадобной информацией и лишней перегрузке на системную шину и шину памяти. Не считая того, очень кэшируемый размер кэш-памяти не должен соответствовать очень вероятному устанавливаемому размеру оперативки в системе. Если возникнет ситуация, когда оперативки окажется больше, чем быть может кэшировано, то в кэш-памяти будет находиться информация лишь из нижнего сектора оперативки. Конкретно таковой была ситуация с платформой Socket7/Super7. Наборы микросхем для данной для нас платформы дозволяли применять огромные объемы оперативки (от 256 Мбайт до 1 Гбайт), в то время как кэшируемый размер нередко был ограничен первыми 64 Мбайт (речь идет о B-cache, находящемся на системной плате) из-за использования дешевеньких 8-бит микросхем теговой SRAM (2 бита из которых резервировалось под указатели реальности и измененности строчки). Это приводило к осязаемому падению производительности.
Какая информация содержится в тегах кэш-памяти? Это информация о адресах, но как можно буквально показать размещение строчки кэш-памяти на всем пространстве кэшируемого размера оперативки, используя настолько незначимое количество адресных битов? Это понятие является базовым в осознании принципов функционирования кэш-памяти. Разглядим предшествующий пример, с 11-бит тегами. Беря во внимание логическое сегментирование благодаря двухканальной ассоциативности, можно разглядывать данную кэш-память как состоящую из 2-ух независящих частей по 512 Кбайт любой. Представим оперативную память как состоящую из «страничек» по 512 Кбайт любая — их будет соответственно 2048 штук. Дальше, Iog2 (2048) = 11 (основание логарифма равно 2, потому что вероятны лишь два логических состояния всякого бита). Это значит, что практически тег — не номер отдельной строчки кэш-памяти, а номер «странички» памяти, на которую отображается та либо другая строчка. Иными словами, в границах «странички» сохраняется прямое соответствие ее «строк» с надлежащими строчками кэш-памяти, т. е. п-я строчка кэш-памяти соответствует n-й «строке» данной «странички» оперативки.
Разглядим механизм работы кэш-памяти различных видов ассоциативности. Допустим, имеется абстрактная модель с восемью строчками кэш-памяти и 64 эквивалентными строчками оперативки. Требуется поместить в кэш строчку 9 оперативки (заметим, что все строчки нумеруются от нуля и по растущей). В модели с прямым отображением эта строчка может занять лишь одно пространство: 9 mod 8=1 (вычисление остатка от деления нацело), т. е. пространство строчки 1. Если взять модель с двухканальной ассоциативностью, то эта строчка может занять одно из 2-ух мест: 9 mod 4=1, т. е. строчку 1 хоть какого канала (сектора). Полноассоциативная модель предоставляет свободу для размещения, и данная строчка может занять пространство хоть какой из восьми имеющихся. Иными словами, практически имеется 8 каналов, любой из которых состоит из 1 строчки.
Ни одна из вышеуказанных моделей не дозволит, очевидно, поместить в кэш больше строк, чем он на физическом уровне в состоянии расположить, они только дают разные варианты, различающиеся балансом эффективности использования кэша и скорости доступа к нему.
Типы подключения кэш-памяти
Количество портов чтения-записи кэш-памяти — показатель того, сколько одновременных операций чтения-записи быть может обработано. Хотя твердых требований и нет, определенное соответствие набору многофункциональных устройств ЦП обязано выслеживаться, потому что отсутствие вольного порта во время выполнения команды приведет к принужденному простою.
Существует два главных метода подключения кэшпамяти к ЦП для чтения: сквозной и побочный (Look-Through и Look-Aside). Сущность первого в том, что по мере необходимости данные поначалу запрашиваются у контроллера кэш-памяти самого высочайшего уровня, который инспектирует состояние присоединенных тегов и возвращает или подходящую информацию, или отрицательный ответ, и в этом случае запрос перенаправляется в наиболее маленький уровень иерархии кэш-памяти либо в оперативку. При реализации второго метода чтения запрос сразу направляется как кэш-контроллеру самого высочайшего уровня, так и остальным кэш-контроллерам и контроллеру оперативки. Недочет первого метода очевиден: при отсутствии инфы в кэше высочайшего уровня приходится повторять запрос, и время простоя ЦП возрастает. Недочет второго подхода — высочайшая избыточность операций и, как следствие, «засорение» внутренних шин ЦП и системной шины ненадобной информацией. Разумно представить, что если для кэшей L1 оптимальна сквозная схема, то для T-кэш. Локальным именуют кэш, находящийся или в ядре ЦП, или на той же кремниевой подложке либо в корпусе ЦП, удаленным — размещенный на системной плате. Соответственно локальным кэшем управляет контроллер в ядре ЦП, а удаленным — НМС системной платы. Локальный кэш исходя из убеждений быстродействия лучше, потому что интерфейс к удаленному кэшу обычно мультиплексируется с системной шиной. С одной стороны, когда иной ЦП захватывает общую системную шину либо какой-нибудь периферийный контроллер обращается к памяти впрямую, удаленный кэш может оказаться временно труднодоступным. С иной — таковой кэш легче применять в многопроцессорных системах.
Есть два всераспространенных метода записи в кэш: сквозной (Write-Through) и оборотной (Write-Back) записи. В первом случае информация сразу сохраняется как в текущий, так и в наиболее маленький уровень иерархии кэш-памяти (либо прямо в оперативку при отсутствии такого). Во 2-м — данные сохраняются лишь в текущем уровне кэш-памяти, при всем этом возникает ситуация, когда информация в кэше и оперативки различается, при этом крайняя становится устаревшей. Для того чтоб при сбросе кэша информация не была необратимо потеряна, к каждой строке кэша добавляется «грязный» бит (dirtybit, по другому узнаваемый как modified). Он нужен для обозначения того, соответствует ли информация в кэше инфы в оперативки, и следует ли ее записать в память при сбросе кэша.
Также следует упомянуть метод резервирования записи (writeallocation). При записи данных в оперативную память нередко возникает ситуация, когда записываемые данные могут скоро пригодиться, тогда и их придется достаточно длительно подгружать. Резервирование записи дозволяет отчасти решить эту делему: данные записываются не в оперативную память, а в кэш. Строчка кэша, заместо которой записываются данные, вполне выгружается в оперативную память. Потому что вновь записанных данных обычно недостаточно для формирования полной строчки кэша, из оперативки запрашивается недостающая информация. Когда она получена, новенькая строчка записывается, и тег обновляется. Определенных преимуществ либо недочетов таковой подход не имеет — время от времени это может отдать незначимый прирост производительности, но также и привести к засорению кэша ненадобной информацией.
Повышение кэша и тестирование
INEL
&
AMD
Первичная причина роста размера встроенного кэша может заключаться в том, что кэш-память в современных микропроцессорах работает на той же скорости, что и сам машина — комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач) (либо вычислительной системы) которое делает арифметические и логические операции данные программкой преобразования инфы управляет вычислительным действием и коор. Частота микропроцессора в этом случае никак не меньше 3200 MГц. Больший размер кэша дозволяет микропроцессору держать огромные части кода готовыми к выполнению. Таковая архитектура микропроцессоров сфокусирована на уменьшении задержек, связанных с простоем микропроцессора в ожидании данных. Современные программки, в том числе игровые, употребляют огромные части кода, который нужно извлекать из системной памяти по первому требованию микропроцессора. Уменьшение промежутков времени, уходящих на передачу данных от памяти к микропроцессору, — это надежный способ роста производительности приложений, требующих интенсивного взаимодействия с памятью. кэш L3 имеет мало наиболее высочайшее время ожидания, чем L 1 и 2, это полностью естественно. Хоть он и медлительнее, но все-же он существенно наиболее резвый, чем рядовая память. Не все приложения выигрывают от роста размера либо скорости кэш-памяти. Это очень зависит от природы приложения.
Если большенный размер встроенного кэша — это отлично, тогда что все-таки задерживало Intel и AMD от данной для нас стратегии ранее? Обычным ответом является высочайшая себестоимость такового решения. Резервирование места для кэша весьма недешево. Обычный 3.2GHzNorthwood содержит 55 миллионов транзисторов. Добавляя 2048 КБ кэша L3, Intel идет на повышение количества транзисторов до 167 миллионов. Обычной математический расчет покажет нам, что EE — один из самых дорогих микропроцессоров.
веб-сайт AnandTech провел сравнительное тестирование 2-ух систем, любая из которых содержала два микропроцессора – IntelXeon 3,6 ГГц в одном случае и AMDOpteron 250 (2,4 ГГц) – в другом. Тестирование проводилось для приложений ColdFusionMX 6.1, PHP 4.3.9, и Microsoft .NET 1.1. Конфигурации выглядели последующим образом:
AMD
— Dual Opteron 250;
— 2 ГБ DDR PC3200 (Kingston KRX3200AK2);
— системнаяплатаTyanK8W;
— ОС Windows 2003 Server Web Edition (32 бит);
— 1 твердый IDE 40 ГБ 7200 rpm, кэш 8 МБ
Intel
— Dual Xeon 3.6 ГГц;
— 2 ГБDDR2;
— материнскаяплатаIntelSE7520AF2;
— ОС Windows 2003 Server Web Edition (32 бит);
— 1 твердый IDE 40 ГБ 7200 rpm, кэш 8 МБ
На приложениях ColdFusion и PHP, не оптимизированных под ту либо иную архитектуру, чуток резвее (2,5-3%) оказались Opteron’ы, зато тест с .NET показал поочередную приверженность Microsoft платформе Intel, что позволило паре Xeon’ов вырваться вперед на 8%. Вывод полностью очевиден: используя ПО Microsoft для Интернет-приложений, есть смысл избрать микропроцессоры Intel, в остальных вариантах несколько наилучшим выбором будет AMD.
Вывод
Анализ изложенного выше материала дозволяет создать заключение, что в согласовании с каноническими теориями, современные производители обширно употребляют кэш-память при построении новейших микропроцессоров. Почти во всем, их потрясающие свойства по быстродействию достигаются конкретно благодаря применению кэш-памяти второго и даже третьего уровня. Данный факт подтверждает теоретические выкладки Гарвардского института о том, что ввиду деяния принципа локальности инфы в современных компах применение кэш-памяти смешанного типа дозволяет достигнуть потрясающих результатов в производительности микропроцессоров и понижает частоту нужных воззваний к главный памяти.
Налицо широкие перспективы предстоящего внедрения кэш-памяти в машинках новейшего поколения, но существующая проблематика невозможности нескончаемого роста кэша, также высочайшая себестоимость производства кэша на одном кристалле с микропроцессором, ставит перед конструкторами вопросцы о некоем высококачественном, а не количественном видоизменении либо скачке в принципах, или огранизации кэш-памяти в микропроцессорах грядущего.
К данной работе были применены материалы:
1.
HTTP
://
www
.
intuit
.
ru
/
department
/
hardware
/
csorg
/9/2.
html
—- 9. Лекция: Организация памяти вычислительной системы
2.
Э.Танненбаум,Современные операционные системы, Питер 2002.1024 с.
3.
Р.Столлинз Операционные системы. М.: Вильямз, 2002. – 600 с.
4.
В.Г.Олифер, Н.А.Олифер Сетевые операционные системы. Питер, 2001.- 554 с.
]]>