

Учебная работа. Курсовая работа: Проектирование базы данных 4
УрГУПС
Кафедра «Связь»
Курсовая работа.
Проектирование базы данных.
работу выполнил:
студент гр. Ит-314
Медведев Н.В.
работу проверил:
педагог
Пащенко М.А.
Екатеринбург,
2006 г.
Содержание
Введение 3
Инфологическое проектирование 5
1.1. Описание предметной области 5
1.2. Описание информационных потребностей юзеров 5
1.3. Построение инфологической модели 6
Даталогическое проектирование 7
2.1. Выбор и черта СУБД 7
2.2. Построение даталогической модели 9
2.3. Создание базы данных 11
2.4. Наполнение БД 12
2.5. Запросы к БД 14
Заключение 17
Перечень использованной литературы 18
Введение.
Под базой данных понимается беспристрастная форма представления и организации совокупы данных, систематизированная таковым методом, чтоб эти данные могли быть найдены и обработаны при помощи ЭВМ .
Система управления базой данных — это совокупа языковых и программных средств, созданных для сотворения, ведения и коллективного использования БД.
Проектирование БД представляет собой непростой трудозатратный процесс отображения предметной области во внутреннюю модель данных. В процессе проектирования разрабатывается модели различных уровней архитектуры БД, проверяется возможность отображения объектов одной модели объектами иной модели.
При проектировании базы данных решаются две главных трудности:
· Каким образом показать объекты предметной области в абстрактные объекты модели данных, чтоб это отображение не противоречило семантике предметной области, и было по способности наилучшим (действенным, комфортным и т.д.)? Нередко эту делему именуют неувязкой логического проектирования баз данных.
· Как обеспечить эффективность выполнения запросов к базе данных, т.е. каким образом, имея в виду индивидуальности определенной СУБД, расположить данные во наружной памяти, создание каких доп структур (к примеру, индексов) востребовать и т.д.? Эту делему именуют неувязкой физического проектирования баз данных.


Проектирование наружных и концептуальной инфологических моделей
Предварительное планирование
Этапы проектирования базы данных.


Рис.1 Этапы проектирования БД
Инфологическое проектирование
1.1
Описание предметной области
Предметная область определяется при помощи 4 главных составляющих:
— объект
— Свойство
— Связь
— Время
В данном курсовом проекте предметной областью является «спортивное общество», а поточнее, те люди, которые интересуются футболом и смотрят за плодами игр.
Требуется создать базу данных для букмекерской конторы, чтоб стремительно определять результаты игр установок в разных чемпионатах, составы этих установок, тренеров и другую информацию о команде. Информация о играх будет браться из федерации футбола.
В базе данных будет храниться информация о результатах игр разных чемпионатах, составах установок, тренеров и т.д.
1.2. Описание информационных потребностей юзеров
Главные юзеры данной базы данных это люди, интересующиеся футболом и следящие за плодами игр. С помощью БД они могут выяснить какая команда наиболее перспективна для ставок, а какая напротив «черная лошадь». Можно просмотреть результаты игры отдельной команды в различных чемпионатах. По БД быть может составлен рейтинг команды. Выяснить информацию о команде, о сыгранных матчах в определенное время.
Главными понятиями ER-модели являются суть, связь и атрибут:
Суть
– это настоящий либо представляемый объект, информация о котором обязана сохраняться и быть доступна. В диаграммах ER-модели суть представляется в виде прямоугольника, содержащего имя сути. При всем этом имя сути — это имя типа, а не некого определенного экземпляра этого типа.
Любой экземпляр сути должен быть отличим от хоть какого другого экземпляра той же сути (это требование в неком роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
Связь
– это графически изображаемая ассоциация, устанавливаемая меж 2-мя сущностями. Эта ассоциация обычно является бинарной и может существовать меж 2-мя различными сущностями либо меж сутью и ей самой (рекурсивная связь).
Связь представляется в виде полосы. При всем этом над местом «стыковки» связи с сутью ставится символ «∞» либо буковка «M», если для данной сути в связи могут употребляться много (many) экземпляров сути, и цифра «1», если в связи может участвовать лишь один экземпляр сути.
Как и суть, связь – это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
Атрибутом
сути является неважно какая деталь, которая служит для уточнения, идентификации, систематизации, числовой свойства либо выражения состояния сути. Имена атрибутов заносятся в прямоугольник, изображающий суть, под именованием сути и изображаются малыми знаками, может быть, с примерами.
Одно из главных требований к организации базы данных – это обеспечение способности отыскания одних сущностей по значениям остальных, для чего же нужно установить меж ними определенные связи.
Связь – ассоциирование 2-ух либо наиболее сущностей. Ниже приведена диаграмма ER-типов, на которой определены связи меж сущностями.
Построение инфологической модели
Инфологическая модель для базы данных «Результаты игр футбольной команды» проектировалась, как модель «Суть-связь».
Суть – это класс однотипных объектов. процесс деятельности конторы идентифицирует такие сути
Любая из сущностей имеет собственный набор атрибутов.
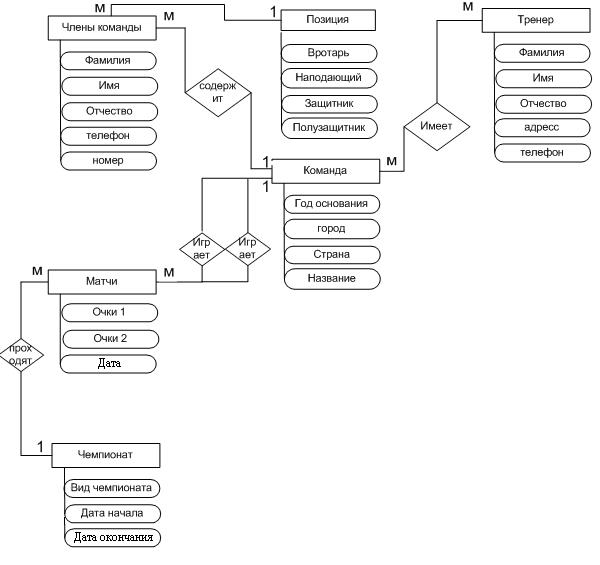

Набросок 1. Диаграмма ER – типов.
Описание сущностей:
2. Даталогическое проектирование.
2.1. Выбор и черта СУБД
Система управления базой данных (СУБД) представляет собой набор программных средств, средством которого осуществляется управление базой данных и доступ к данным.
К числу главных функций СУБД принято относить последующие:
Эта функция заключается в обеспечении нужных структур наружной памяти, как для хранения конкретных данных, входящих в БД, так и для служебных целей. СУБД поддерживает свою систему именования объектов БД.
СУБД обычно работают с БД значимого размера. Этот размер значительно превосходит доступный размер оперативки. При воззвании к хоть какому элементу данных делается обмен с наружной памятью, и система работает со скоростью устройства наружной памяти. Единственным методом роста данной скорости является буферизация данных в оперативки. Потому в СУБД поддерживается набор буферов оперативки с дисциплинами подмены буферов.
Транзакция – это последовательность операций над БД, рассматриваемых СУБД как единое целое. Или транзакция удачно производится и СУБД фиксирует (COMMIT) конфигурации БД, произведенные ею во наружной памяти, или ни одно из этих конфигураций никак не отражается на состоянии БД.
СУБД обязана обеспечивать надежное хранение данных во наружной памяти, т.е. СУБД обязана иметь возможность вернуть крайнее согласованное состояние БД опосля хоть какого аппаратного либо программного сбоя.
Для работы с БД употребляются особые языки баз данных. Почаще всего выделяются 2 языка – язык определения данных (DDL) и язык манипулирования данными (DML). DDL служит, основным образом, для определения логической структуры БД, а DML, содержит набор операторов манипулирования данными. В почти всех СУБД обычно поддерживается единый встроенный язык, содержащий все нужные средства для работы с БД. Обычным языком реляционных СУБД является язык SQL. Язык SQL соединяет средства DDL и DML, т.е. дозволяет определять схему реляционной БД и манипулировать данными.
В SQL употребляются последующие главные типы данных, форматы которых могут несколько различаться для различных СУБД:
— целое число (обычно до 10 означающих цифр и символ);
— «куцее целое» (обычно до 5 означающих цифр и символ);
— десятичное число, имеющее p цифр (0<p<16) и символ; при помощи q задается число цифр справа от десятичной точки (q<p, если q = 0, оно быть может опущено);
— вещественное число с 15 означающими цифрами и целочисленным порядком, определяемым типом СУБД;
— символьная строчка фиксированной длины из n знаков (0<n<256);
— символьная строчка переменной длины, не превосходящей n знаков (n>0 и различное в различных СУБД, но не меньше 4096);
— дата в формате, определяемом специальной командой (по дефлоту mm/dd/yy); поля даты могут содержать лишь настоящие даты, начинающиеся за несколько 1000-летий до н.э. и ограниченные пятым-десятым тысячелетием н.э.;
— для научных вычислений 15 цифр точности.
— численные значения содержат числа от 0 до 9 и необязательные символ и десятичную точку.
Потому при проектировании БД выбор тормознул на СУБД InterBase 6.0, как СУБД поддерживающей все главные выше перечисленные функции. Кроме этого InterBase 6.0 имеет последующие свойства:
InterBase реализует архитектуру множественных поколений записей (
— Multi-Generational Architecture).
обеспечивает неповторимые способности использования версий, что ведет к высочайшей степени доступности данных как для юзеров, работающих с транзакциями, так и для юзеров, использующих приложения поддержки принятия решений. Механизм MGA в InterBase отлично работает при оперативной обработке маленьких транзакций (
— On-Line Transaction Processing) и является неповторимым для крупномасштабных настоящих приложений, превосходя остальные базы данных в области параллельного выполнения долгих транзакций для поддержки принятия решений. Механизм версий избавляет необходимость блокировки записей, к которым осуществляется доступ по чтению во время транзакции, делая их вольными от конфликтов доступа – доступ по чтению никогда не перекрывает доступ по записи. В отличие от остальных баз данных, InterBase обеспечивает своевременные, стабильно воспроизводимые результаты для всякого запроса без специального программирования. В итоге достигается наибольшая пропускная способность для всех пользовательских транзакций.
InterBase добавляет многопотоковую архитектуру к MGA, улучшая производительность и оптимизируя внедрение системных ресурсов, в особенности при большенном числе юзеров. Многопотоковая архитектура обеспечивает разделяемый кэш данных, сокращая число дисковых операций ввода-вывода для всякого запроса в приложении. Разделяемый кэш метаданных на сервере уменьшает стоимость компиляции для запросов и делает выполнение хранимых процедур и триггеров наиболее действенным. Статистика по юзерам и по базе данных, хранимая сервером, полезна при диагностике критичных точек производительности приложения.
Почти всем приложениям (мультимедиа, научные, веб – приложения), требуется возможность обработки неструктурированных данных. InterBase является первой реляционной базой данных, удовлетворившей это требование при помощи BLOB. Внедрение BLOB дозволяет сохранять в базе данных аудио-, видео-, графическую и бинарную информацию. В современных приложениях фильтры BLOB употребляются для сжатия и трансформации данных. Разработка приложений и усовершенствованная производительность для научных приложений поддерживаются многомерными типами данных InterBase, обеспечивающими хранение до 16 измерений в одном поле базы данных.
Сигнализаторы событий оповещают «заинтригованные стороны» о специфичных измнениях, произошедших в базе данных. приложение регистрирует энтузиазм к событию и потом ожидает без опроса базы данных оповещения о пришествии действия. За счет устранения опроса сигнализаторы событий сберегают системные ресурсы и обеспечивают масштабируемость приложений.
Компактность ядра InterBase сберегает драгоценное дисковое место для его следующего использования критически необходимыми бизнес-приложениями. InterBase так же обеспечивает производительность, сравнимую с конкурирующими базами данных, при наименьших требованиях к оперативки для доборной экономии на цены памяти. Развертывание сервера состоит из 1-го исполняемого файла и представляет собой обычный машинный процесс, что упрощает установку даже заказных приложений.
InterBase держится серьезного соответствия промышленным эталонам для клиент-серверных вычислительных сред, таковым как ANSI/SQL, Java, UNICODE и XDR (External Data Representation – наружное время, нужное для разработки, внедрения и сопровождения ваших приложений на огромном количестве платформ с гарантией незамедлительного заслуги наивысшей производительности.
2.2. Построение даталогической модели
На этом шаге нужно установить соответствие меж сущностями и чертами предметной области и отношениями и атрибутами в InterBase 6.0. Для этого необходимо каждой сути и чертам поставить в соответствие набор отношений (таблиц) и их атрибутов (полей).
Ключ – это малый набор атрибутов, по значениям которых можно совершенно точно отыскать требуемый экземпляр сути. Минимальность значит, что исключение из набора хоть какого атрибута не дозволяет идентифицировать суть по оставшимся. Любая суть владеет хотя бы одним вероятным ключом. один из их принимается за первичный ключ. При выбирании первичного ключа следует отдавать предпочтение несоставным ключам либо ключам, составленным из малого числа атрибутов. Нецелесообразно также употреблять ключи с длинноватыми текстовыми значениями (лучше употреблять целочисленные атрибуты). Атрибут либо группа атрибутов, которые в рассматриваемой таблице не являются первичным ключом, а в связной таблице – являются, именуется наружным ключом.
Таблица соответствий заглавий сущностей.
Суть
Соответствие
Команда
Team
Члены команды
Ludi
Матчи
Matchi
Тренер
Trener
Чемпионат
Chemp
Работает
Work1
Позиция
Pozitziya
Таблица соответствий заглавий полей.
Атрибуты
Соответствие
Фамилия
Famil
имя
Imya
Отчество
Otchestvo
телефон
Tel
Команда 1
Komanda_1
Команда 2
Komanda_2
Очки 1
ochki_1
Очки 2
ochki_2
время
Vremya
Вид чемпионата
Vid_chemp
Год оснавания
God_osn
город
Gorod
Страна
Strana
Тренеровочные базы
Basi
адресок
Adres
Заглавие
Nazvanie
Дата начала
Data_nachala
Дата_конца
Data_konza

Набросок 2. Даталогическая модель.
2.3. Создание базы данных
.
Создание таблиц:
Таблица
«Чемпионат
»:
CREATE TABLE «CHEMP» ( «KOD_CHEMP» INTEGER NOT NULL, «VID_CHEMP» VARCHAR(20), «VREMYA» DATE, PRIMARY KEY («KOD_CHEMP»));
Таблица
«Члены
команды
»:
CREATE TABLE «LUDI» («KOD_CHEL» INTEGER NOT NULL, «FAMIL» VARCHAR(20), «IMYA» VARCHAR(20), «OTCHESTVO» VARCHAR(20), «TEL» VARCHAR(20), «KOD_KOMANDI» INTEGER NOT NULL, «NOMER» INTEGER NOT NULL);
ALTER TABLE «LUDI» ADD FOREIGN KEY («KOD_KOMANDI») REFERENCES TEAM («KOD_KOMANDI»);
ALTER TABLE «LUDI» ADD FOREIGN KEY («KOD_KOMANDI») REFERENCES TEAM («KOD_KOMANDI»);
Таблица «Матчи»:
CREATE TABLE «MATCHI» («KOD_K1» INTEGER NOT NULL, «KOD_K2» INTEGER, «OCHKI_1» INTEGER, «OCHKI_2» INTEGER, «KOMANDA_1» VARCHAR(20), «KOMANDA_2» VARCHAR(20), «KOD_KOMANDI» INTEGER NOT NULL, «VREMYA» DATE, «KOD_CHEMP» INTEGER NOT NULL, PRIMARY KEY («KOD_KOMANDI», «KOD_CHEMP»));
ALTER TABLE «MATCHI» ADD FOREIGN KEY («KOD_CHEMP») REFERENCES CHEMP («KOD_CHEMP»);
ALTER TABLE «MATCHI» ADD FOREIGN KEY («KOD_K1») REFERENCES TEAM («KOD_KOMANDI»);
ALTER TABLE «MATCHI» ADD FOREIGN KEY («KOD_K2») REFERENCES TEAM («KOD_KOMANDI»);
Таблица
«Work1»:
CREATE TABLE «WORK1» («KOD_KOMANDI» INTEGER NOT NULL, «KOD_TRENERA» INTEGER NOT NULL, PRIMARY KEY («KOD_KOMANDI», «KOD_TRENERA»));
Таблица
«Команда
».
CREATE TABLE «TEAM» («KOD_KOMANDI» INTEGER NOT NULL, «STRANA» VARCHAR(20), «GOROD» VARCHAR(20), «GOD_OSN» DATE, «NAZVANIE» VARCHAR(20), PRIMARY KEY («KOD_KOMANDI»));
Таблица
«Тренеры
».
CREATE TABLE «TRENER» («KOD_TRENERA» INTEGER NOT NULL, «FAMIL» VARCHAR(20), «IMYA» VARCHAR(20), «OTCHESTVO» VARCHAR(20), «TEL» VARCHAR(20), «ADRES» VARCHAR(20), PRIMARY KEY («KOD_TRENERA»));
Таблица
«Позиция
».
CREATE TABLE «POZITZIYA» ( «KOD_POZITZII» INTEGER NOT NULL,
«POZITZIYA» VARCHAR(20), PRIMARY KEY («KOD_POZITZII»));
2.4. Наполнение БД
Таблица «Чемпионат».

Таблица «Члены установок».

Таблица «Матчи».

Таблица «Команда».

Таблица «Тренер».

Таблица «Work1».

2.5. Запросы к БД
I. Однотабличные запросы:
1. Выводит всех футболистов у кого 1-ая буковка фамилии находится в промежутке от «А» до «Г»:
select famil from ludi where famil >=’А’ and famil < ‘Г’;

2. Выводит всех тренеров у кого 1-ая буковка фамилии находится в промежутке от «А» до «Р»:
select famil from trener where famil >=’А’ and famil < ‘Р’;

3. Выдает всех игроков команды Локомотив:
select famil, imya, otchestvo from ludi where kod_komandi=1;

II. Многотабличные запросы:
1 .Выводит тренеров каждой команды:
select nazvanie, famil from team, trener, work1 where team.kod_komandi=work1.kod_komandi and work1.kod_trenera=trener.kod_trenera;

2. Выводит таблицу игр всех чемпионатов:
select vid_chemp, komanda_1,komanda_2,ochki_1,ochki_1 from chemp, matchi where chemp.kod_chemp=matchi.kod_chemp;

3. Выводит футболистов, кто играет в котором клубе:
select famil, nazvanie from ludi, team where team.kod_komandi=ludi.kod_komandi;

………………………………………….
…………………………………………..
III. С внедрением функций и вычисляемых значений:
1. Вычисляет количество играков команды Локомотв:
select count
kod_chel from ludi where kod_komandi=1;

2. Выводит команду основанную ранее всех:
select min(god_osn) from team;

3. Выводит какое количесво матчей сыграла команда Локомотив:
select count
from matchi where kod_k1=1 or kod_k2=1;

IV. С групповыми операциями
1. Выводит количество играков каждой команды:
selectnazvanie, count(famil) fromludi, teamwhereteam.kod_komandi=ludi.kod_komandigroupbynazvanie;

2. Выводит сколько игр сыграно в любом чемпионате:
select vid_chemp, count(kod_chemp) from chemp, matchi where matchi.kod_chemp=chemp.kod_chemp group by vid_chemp;

Заключение
В итоге выполнения курсового проекта была сотворена база данных по играм футбольных установок в различных чемпионатах. Были разработаны 10 разных запросов, таковых как – однотабличные, многотабличные, запросы с функциями и запросы с групповыми операциями. В курсовом проекте представлены инфологическая и даталогическая модели базы данных. Данная база данных может применяться в букмекерских конторах для резвого получения данных о играх той либо другой команды.
Перечень использованной литературы
1. МАРТИН ГРУБЕР «Осознание SQL»
2. Э.К. Лецкий «Информационные технологии на жд транспорте», М.:УМК МПС Рф, 2000.
]]>